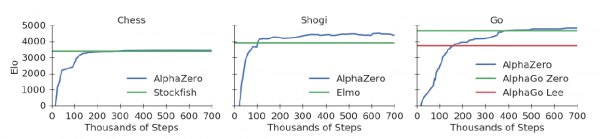
구글 산하 딥마인드(Deep Mind)의 인공지능(AI) 기술이 거듭 진화하고 있다. 딥마인드가 최근 개발한 새로운 인공지능 ‘알파 제로(Alpha Zero)’가 4시간 만에 체스를 정복했다. 쇼기(일본 장기)를 정복하는 데는 2시간이 채 걸리지 않고 바둑을 꺾는 데는 8시간이 걸렸다.

구글 딥마인드는 지난 6일(현지시각) 온라인 논문 저장 사이트 아카이브(arXiv)에 데이비드 실버(David Silver) 딥마인드 수석연구원 등 13명이 공동으로 작성한 ‘범용 강화 학습 알고리즘으로 체스와 쇼기 정복하기(Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm)’ 논문을 게시했다.
아카이브는 출판되지 않은 수학·물리학·천문학 분야 등의 논문을 게시하는 사이트다.
데이비드 수석연구원은 “이번에 선보인 알파 제로는 이전 버전인 알파고 제로(AlphaGo Zero)처럼 인간의 도움 없이 게임 규칙만 입력해 스스로 학습하는 알고리즘이다”면서 “알파고 알고리즘이 바둑에 한정된 것과는 달리 알파 제로는 바둑뿐 아니라 체스 다른 게임에도 적용할 수 있도록 범용화 했다”고 말했다.
알파제로는 지난10월에 선보인 알파고 제로와 같이 인간의 도움을 받지 않고 스스로 학습하는 강화학습(Reinforcement Learning) 방식을 채택했다. 강화학습 방식은 지난해 이후 빠르게 발전하는 영역으로 인공지능이 목적 달성을 위해 스스로 시행착오를 겪으며 문제를 해결하는 것이 특징이다.
기존 기계학습(머신러닝) 기반의 인공지능은 목표 달성을 위해 사람이 일일이 모델링을 해 학습방법을 가르쳐준 반면 강화학습은 빅데이터를 기반으로 스스로 환경을 인식하고 행동하면서 인공지능의 무한한 잠재력을 드러냈다는 평가를 받는다.
데이비드 수석연구원은 논문에서 “새로운 인공지능 알파 제로가 일본 장기(쇼기)를 독학한지 2시간 만에 장기 소프트웨어 엘모(Elmo)를 꺾었다”면서 “체스는 4시간, 바둑은 8시간이 걸렸다”고 설며했다.
알파제로는 심층 신경망을 통해 기존 인공지능 알고리즘보다 효율 있는 사고를 한다. 인공지능 탐색 능력을 비교하면 체스 소프트웨어 스톡피쉬(Stockfish)는 초당 7000만개의 경우의 수를 분석하지만 알파 제로는 초당 8만개 경우의 수를 연구해 약 900배의 효율을 입증했다. 엘모 일본 장기 소프트웨어는 3만5000개 경우의 수를 분석해 알파 제로의 초당 4만개 탐구 능력과 차이를 보였다.
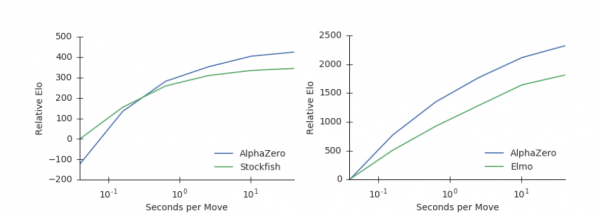
또 알파제로는 탐구하는 시간도 다른 인공지능보다 뛰어나다. 알파제로는 인간이 생각을 오래 할수록 훌륭한 아이디어를 떠올리듯이 다음 수를 분석할 때 시간을 많이 사용할수록 결과물의 질도 향상되는 것으로 파악됐다. 알파제로가 10초를 분석하면 체스 소프트웨어 스톡피쉬보다 100배 우수한 성능을, 쇼기 소프트웨어 엘모와는 약 75배 우수한 결과물을 얻었다.
데이비드 연구원은 “바둑 소프트웨어에서 시작한 인공지능이 거듭 진화해 스스로 학습하는 단계에 이르렀다”면서 “이번에 선보인 알파 제로는 기존 인공지능 알고리즘을 짧은 시간 따라잡을 뿐 아니라 다른 분야로도 적용할 수 있다”고 기대감을 드러냈다.
일본 경제매체 니혼게이자이 신문은 지난 6일 “인공지능이 게임 이외의 분야에서도 인간이 풀지 못하는 어려운 문제를 풀 것으로 기대한다”면서 “딥마인드는 난치병 발견이나 신소재 개발, 등에 인공지능 기술을 응용할 것이다”고 보도했다.